
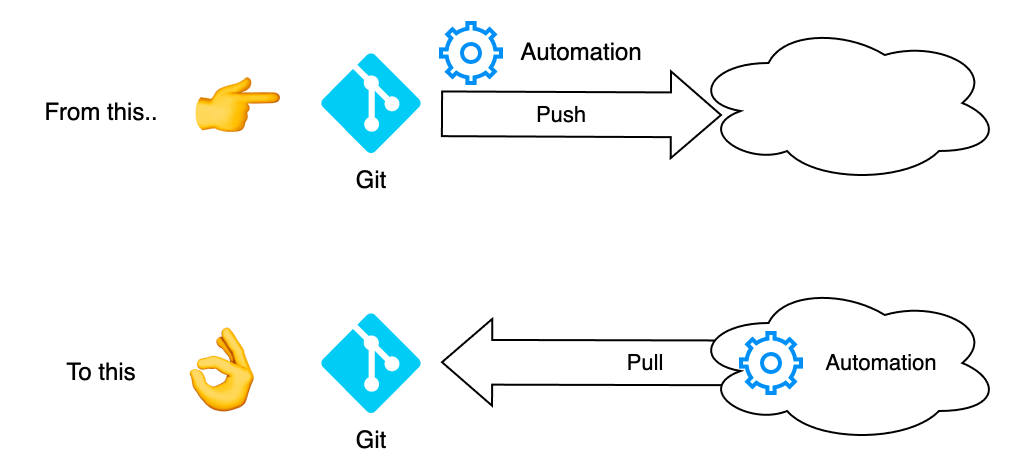
Recently, I have been discussing how CI/CD is shifting from a static Push-based way of work to a pull-based method.
I will discuss what this means, how this way of work may look, and what possibilities this holds.
What is CI/CD?
So, CI/CD refers to Continuous Integration and Continuous Deployment. These are two separate concepts, but they are almost always referred to in the same context, as they are essential to most DevOps-flavored processes.
When writing, building, and merging code, we continuously test the code and make sure that this code integrates nicely with the existing code base. Shift-left on testing and trunk-based development are two great enablers for CI.
On the other hand, CD refers to code continuously being deployed. In the case of Infrastructure as Code, we will automatically deploy changes to our infrastructure. For example, we can trigger deployment when we finish a Pull Request into the main branch of our Git repository.
A crucial component here is automation. By allowing Integration and Deployment to happen with minimal developer interaction, we can maximize efficiency and minimize the cycle time of changes.
These few figures are an example for such a workflow:
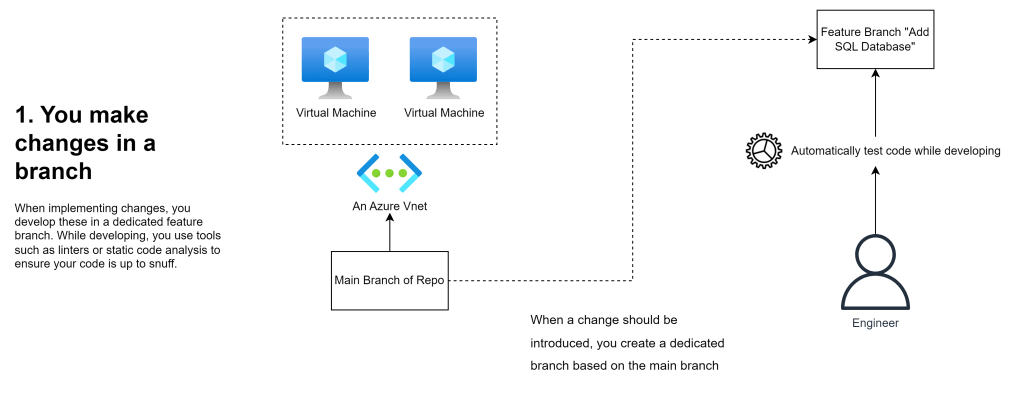
Changes are developed in a branch
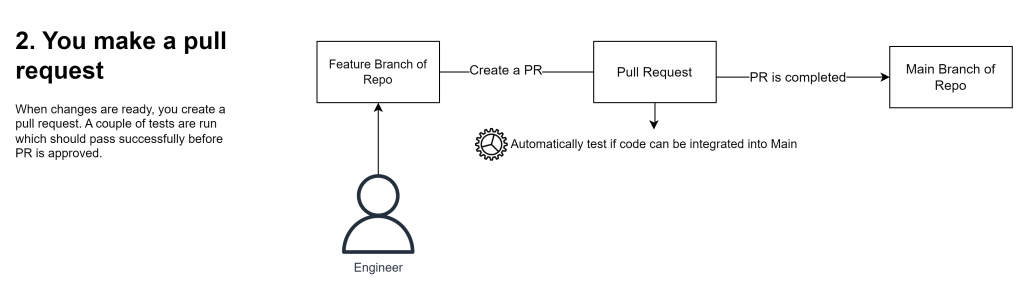
A pull request is made to integrate changes
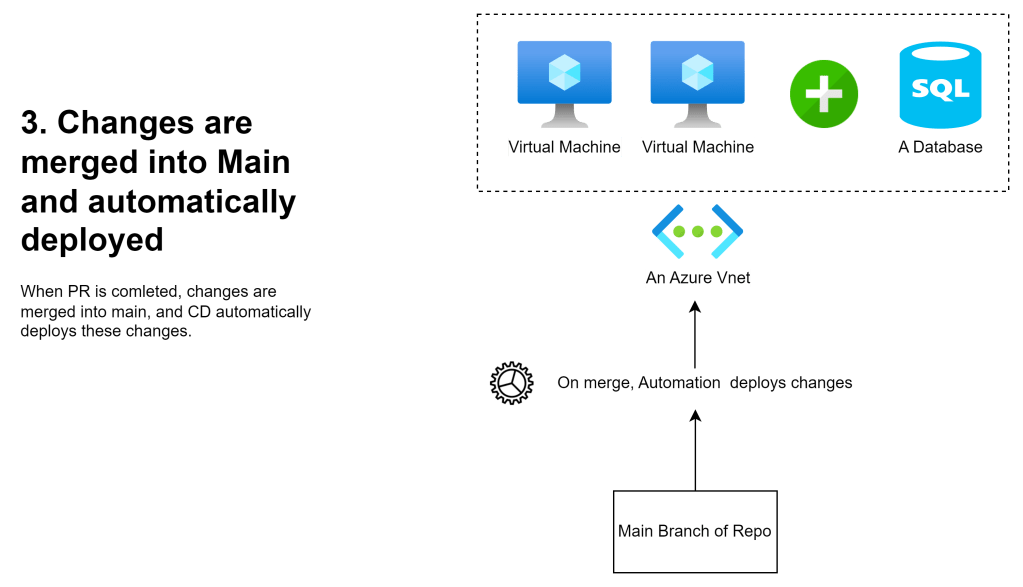
Continuous Deployment automatically deploys changes
The Problem
CI/CD can speed up and make an engineer’s life infinitely easier. However, the workflow I just described is a very static deployment method.
There are three significant gripes I have with a very static approach:
- Static, push-based processes depend on you to take deliberate action to deploy changes.
- The other is that push-based CI/CD is prone to drift, mainly due to CD only happening occasionally. (per nr 1)
- The third is that managing the lifecycles of different components can become a challenge when combining Infrastructure with highly dynamic elements, such as workloads in Kubernetes.
For example, our actual Infrastructure may have changed significantly between two changes. A policy set on the subscription may have added tags or disallowed specific resources, or a piece of Infrastructure may have been changed (or even outright destroyed) manually by accident or due to poor communication.
A concrete example would be that a (relatively) minor change has been made to an Azure VM. If for example automatic updates were suddenly disabled, this would not be something that would trigger an alarm in most cases.
Instead, this could go unnoticed until the next time changes are pushed trough IaC to the infrastructure. The worst case scenario here, could for example be that a couple of critical vulnerabilities were never patched on these VM’s, due to automatic updates being turned of for quite a while.
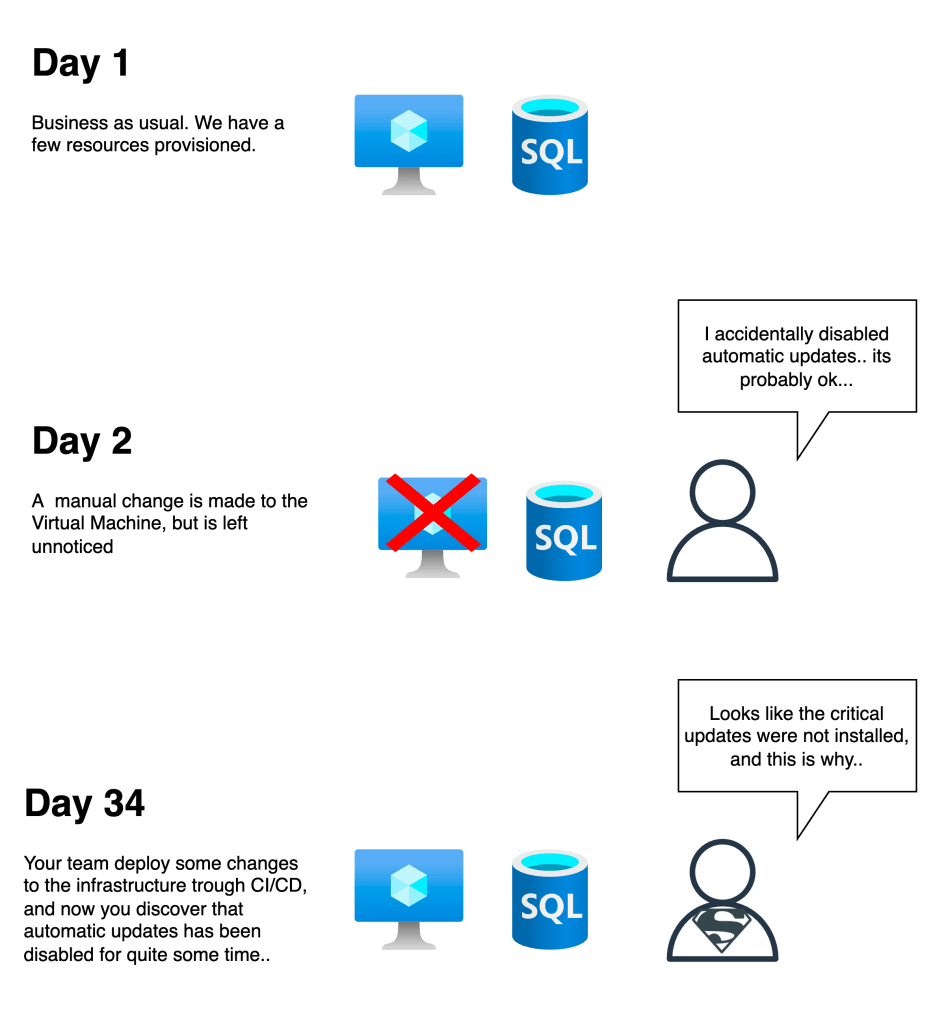
Of course, this is a somewhat contrived example, but the point is that any kind of drift can have ramifications down the road.
The moral of the story is that push-based CI/CD is not well suited for handling drift due to its static, deliberate nature.
Of course, you can run CD on a set schedule or use tools for drift detection, such as driftctl or built-in commands to refresh the infrastructure status (i.e., terraform refresh).
Even if you invest in drift detection, the issue remains that your code is only sometimes a complete source of truth for your Infrastructure until the next time deployment occurs.
Lifecycle of components inside and outside of K8s
So, drift detection is one issue, but another complex issue is how you should manage the lifecycle of resources inside and outside a dynamic environment such as Kubernetes.
Personally I recently encountered ‘issues’ tied to configuring AAD Workload Identity for use in Azure Kubernetes Service.
In short, a Workload Identity provides pods in a cluster a way to get a token from Azure AD and use this for reaching resources in Azure. This necessitates combining the values of objects inside Kubernetes with objects outside Kubernetes.
Using a Workload Identity requires these components:
- A dedicated Kubernetes Service Account
- A User Assigned Managed Identity in Azure
- A Role Assignment in Azure
- A Federated Identity Credential in Azure
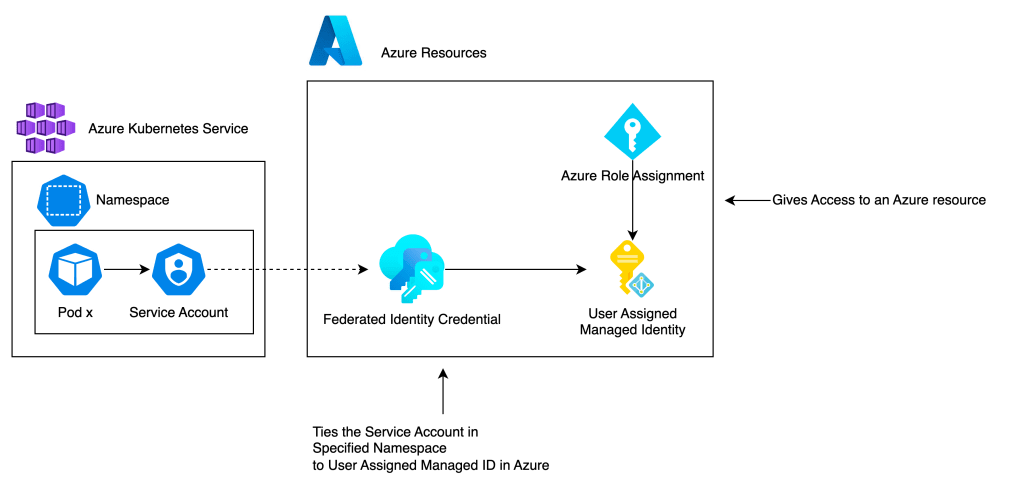
That is not too much to handle.
The problem arises when configuring the Federated identity credential in Azure. This resource requires a reference to both the name of the dedicated Kubernetes Service Account and the name of the namespace of said Service Account, in addition to being attached to the User Assigned Managed Identity.
This federated identity is a part of our Infrastructure but also needs to reference values declared in Kubernetes. Do you see the problem? It is challenging to manage the lifecycle of resources across both Azure and Kubernetes.
One option to resolve this is to create everything through a single tool such as Terraform. Suppose Terraform manages both the Azure resources and the resources in Kubernetes. In such a case, the attributes of Kubernetes resources are available for declaring resources in Azure. And vice versa.
However, I prefer a different approach. While Terraform is a great tool, it could see some improvements in managing Kubernetes. Sure, it works fine for setting up the Infrastructure for running Kubernetes, but I am thinking about the workloads inside Kubernetes.
Terraform is static due to how a deliberate action (a Terraform Apply) is required to deploy our code. On the other hand, Kubernetes is highly dynamic by nature and much better suited for a deployment method such as GitOps.
Enter GitOps
By this point, GitOps is a well-known concept for many.
Contrary to a push-based CI/CD workflow, GitOps continuously pulls configuration from a Git Repo.
GitOps tools accomplish this by having a controller run inside Kubernetes, which continuously (notice that keyword) checks if the contents of the Git repo are updated and if the state of the Kubernetes cluster matches this.
If it does not match, the controller will reconcile the state of the cluster so it accurately matches the code as defined in Git.
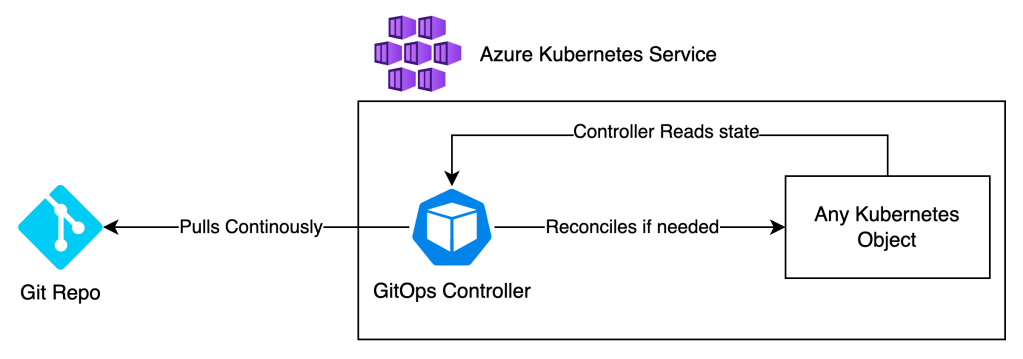
With this method, drift rarely happens, and Git is always the actual source of truth. Deployment is also effortless, as code only needs to be checked into the repo (following a due process), and GitOps takes it from there.
Given our previous example with automatic updates, if GitOps deployed the config, this unintended change is quickly discovered and reconciled!
Now, you might be thinking that GitOps is primarily suited for Kubernetes. And yes, that is correct. Most GitOps offerings rely on a running Kubernetes Cluster. The two most extensive offerings for GitOps, ArgoCD and Flux, are focused on deploying Kubernetes native objects.
While Flux already has an operator for Terraform, what I am most excited about is projects such as Crossplane 🙌
With Crossplane, we can manage resources outside a Kubernetes cluster with the same workflow, syntax, and toolset as any other Kubernetes native object! (Crossplane basically interacts with API’s much the same way that Terraform would!)
Take a look at this yaml manifest, for example:
apiVersion: dbforpostgresql.azure.upbound.io/v1beta1
kind: FlexibleServer
metadata:
name: example-flexible-server
spec:
forProvider:
administratorLogin: psqladmin
administratorPasswordSecretRef:
key: cred
namespace: crossplane-system
name: postgres-secret
location: norwayeast
resourceGroupName: test-rg
skuName: GP_Standard_D4s_v3
storageMb: 32768
version: "12"
This code sets up a flexible PostgreSQL database in Azure. Since this resource is a Kubernetes object, I can deploy it through GitOps and manage this piece of Infrastructure as part of the same lifecycle as the other workloads in Kubernetes.

Combined, this dramatically lessens the risk of drift due to the reconciling nature of GitOps, but it also helps alleviate the cognitive load of a developer. For example, a developer deploying to a Crossplane platform would only need to know how to develop and write code for Kubernetes and not juggle many different tools and skill sets.
The ideal
So, to reiterate, we should look to have all code, both Infrastructure and application, consolidated in terms of workflow and use Git as a single source of truth. This goal is made possible through projects such as Crossplane and enables excellent benefits in terms of lifecycle management, automatic reconciliation, lessening the cognitive load of developers, and more!
While a push-based CI/CD works excellently in many circumstances, a few issues inhibit efficiency and ability to reconcile, especially in highly dynamic environments.
Thanks for reading!
As always, I appreciate you taking the time to read my post and feel free to let me know what to cover next. Maybe we can take a closer look at GitOps in practice next time?

Leave a comment